生产者发送流程:

分区好处:

分区策略:
方便在集群中扩展:每个partion可以通过调整以适应它所在的机器,而一个topic又可以有多个partition组成,因此整个集群就可以适应任意大小的数据了.
可以提高并发:因为可以以partition为单位读写了.
分区的原则:

A:指明partition的情况下,直接将指明的值直接作为partition值;
B:没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
C:既没有partition值又没有key值的情况下,kafka采用StickyPartition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,kafka再随机一个分区进行使用. 例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到,kafka再随机一个分区进行使用(如果还是0会继续随机)
生产者如何提高吞吐量:

数据可靠性保障:
A:生产者发送数据到topic partition的可靠性保证
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack响应,如果producer收到ack,说明消息发送成功,否则重新发送数据.

B:Topic partition存储数据的可靠性保证
副本数据同步策略
|
方案
|
优点
|
缺点
|
|
半数以上完成同步,就发送ack消息
|
延迟低
|
选举新的leader时,容忍n台节点的故障,需要2n+1个副本
|
|
全部完成同步,就会发送ack消息
|
选举新的leader时,容忍n台节点的故障,需要n+1个副本
|
延迟高
|
ISR
ACK应答级别
这一操作提供了一个最低的延迟,partition的leader接收消息还没有写入磁盘已经返回ack,当leader故障时有可能丢失数据.
partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据.
partition的leader和follower全部写入磁盘成功后才发送ack,但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复.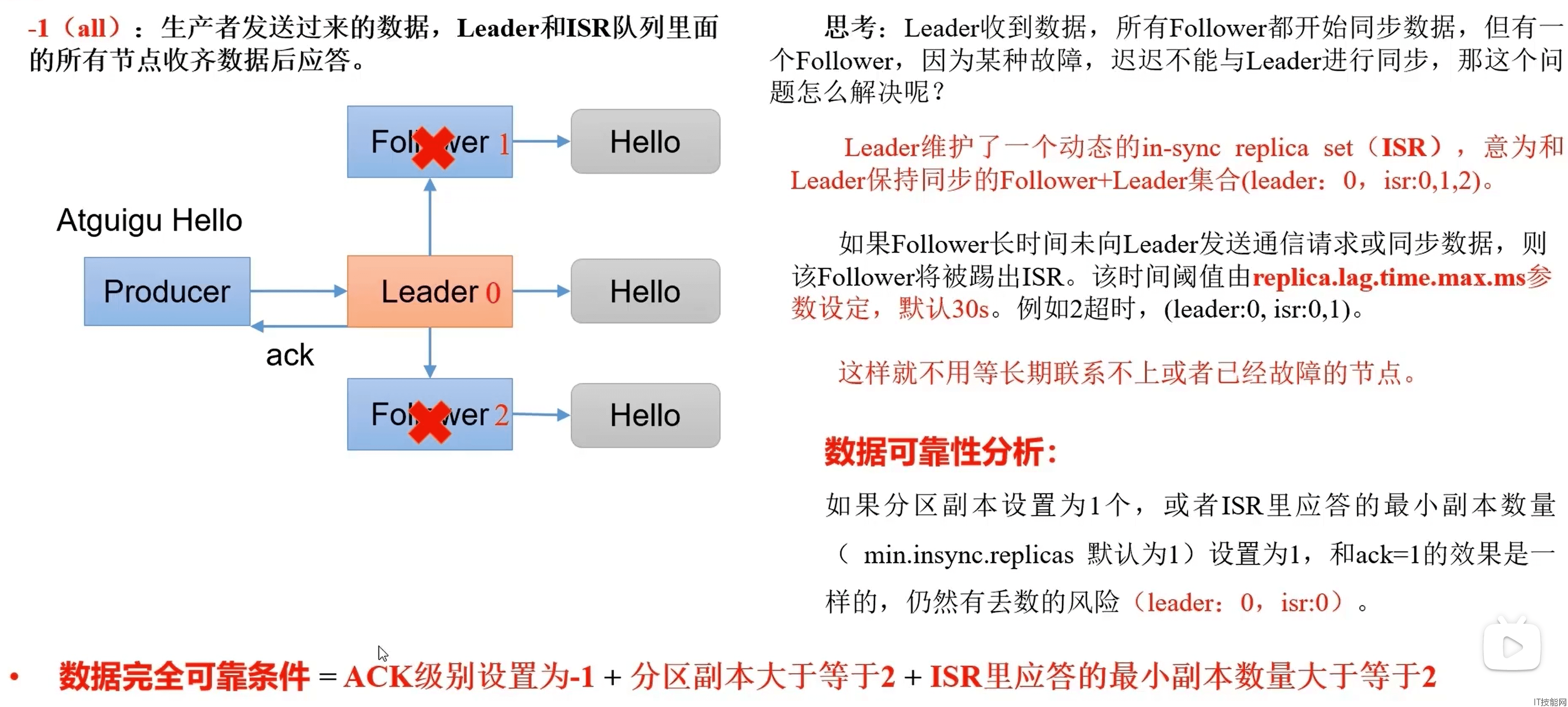

Exactly Once语义
