HBase 整体结构:
- Table 中的所有行都按照 Row Key 的字典序排列。
- Table 在行的方向上分割为多个 HRegion。
- HRegion按大小分割的(默认10G),每个表一开始只有一 个HRegion,随着数据不断插入表,HRegion不断增大,当增大到一个阀值的时候,HRegion就会等分会两个新的HRegion。当Table 中的行不断增多,就会有越来越多的 HRegion。
- HRegion 是 HBase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 HRegion 可以分布在不同的 HRegion Server 上。但一个 HRegion 是不会拆分到多个 Server 上的。
- HRegion 虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion 由一个或者多个 Store 组成,每个 Store 保存一个 Column Family。每个 Strore 又由一个 MemStore 和0至多个 StoreFile 组成。如上图。
StoreFile 和 HFile 结构
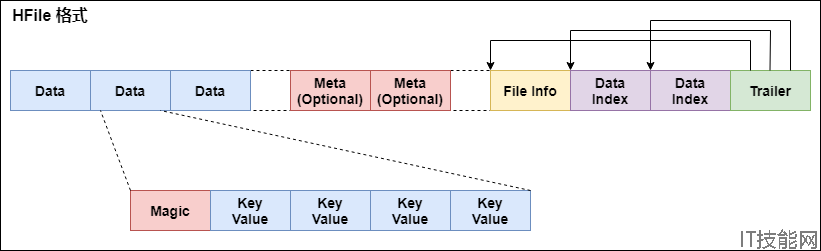
StoreFile以HFile格式保存在HDFS上。HFile的格式为:

首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数 据块的起始点。
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:
HFile 具体结构:
开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HFile分为六个部分:
Data Block 段–保存表中的数据,这部分可以被压缩.
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
File Info 段–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer–这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目前HFile的压缩支持两种方式:Gzip,Lzo。
Memstore与StoreFile
一个 HRegion 由多个 Store 组成,每个 Store 包含一个列族的所有数据 Store 包括位于内存的 Memstore 和位于硬盘的 StoreFile。
写操作先写入 Memstore,当 Memstore 中的数据量达到某个阈值,HRegionServer 启动 FlashCache 进程写入 StoreFile,每次写入形成单独一个 StoreFile。
当 StoreFile 大小超过一定阈值后,会把当前的 HRegion 分割成两个,并由 HMaster 分配给相应的 HRegion 服务器,实现负载均衡。
客户端检索数据时,先在memstore找,找不到再找storefile。
HLog(WAL log)
WAL 意为Write ahead log,类似 mysql 中的 binlog,用来 做灾难恢复时用,Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
每个Region Server维护一个Hlog,而不是每个Region一个。这样不同region(来自不同table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。带来的麻烦是,如果一台region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其它region server上进行恢复。
HLog文件就是一个普通的Hadoop Sequence File:
1.HLog Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。 2.HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。